RESEARCH
Memory System
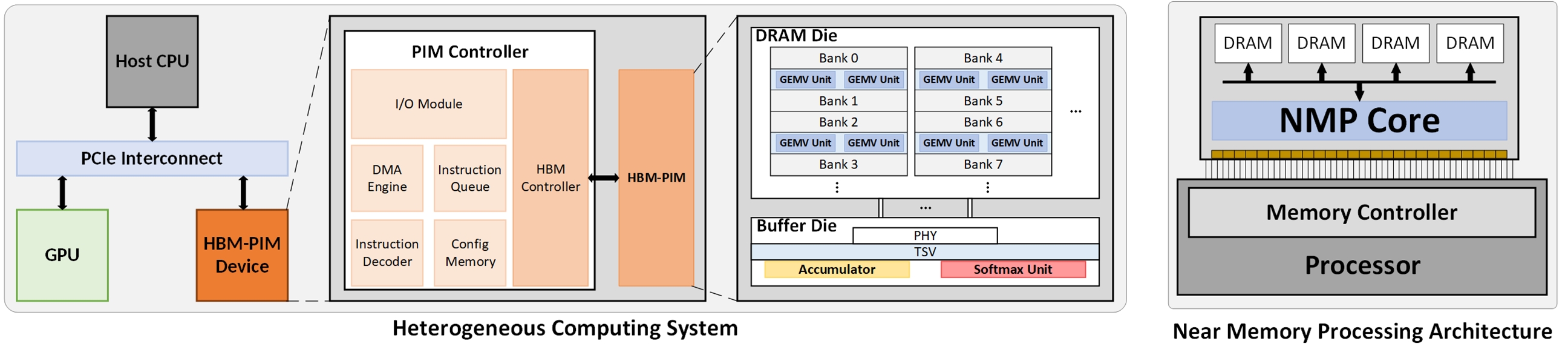
- Heterogeneous Computing System
A Heterogeneous Computing System combines multiple processing units like CPUs, GPUs, and Processing-in-Memory (PIM) devices, often utilizing High Bandwidth Memory (HBM-PIM) or GDDR-PIM. Modern workload, particularly large models like transformer-based LLMs, face significant data transfer bottlenecks due to extensive data movement. By intelligently analyzing the dataflow, a heterogeneous system can assign different computational tasks to the most appropriate device (CPU, GPU, or PIM). This strategy minimizes data transfers across slower external bandwidth, allowing computations to happen closer to the data (especially on HBM-PIM), thereby effectively alleviating the memory bandwidth bottleneck and improving performance and efficiency for memory-bound operations. - Near Memory Processing
For many data-intensive applications, including machine learning and image processing, system performance degradation is often caused by the memory bandwidth bottleneck problem rather than a simple lack of processing capability. The extensive movement of data between the CPU and memory creates a performance wall. To overcome this, Near Memory Processing (NMP) and Processing in Memory (PIM) are gaining significant attention. This approach involves executing certain operations close to the DRAM, utilizing a dedicated NMP Core situated near the memory controller and DRAM banks, instead of solely relying on the CPU for all computations. This proximity drastically reduces data transfer latency and energy. The goal is to research and design novel NMP/PIM architectures to substantially improve the performance of running memory-bounded applications that are bottlenecked by data movement.
Accelerator
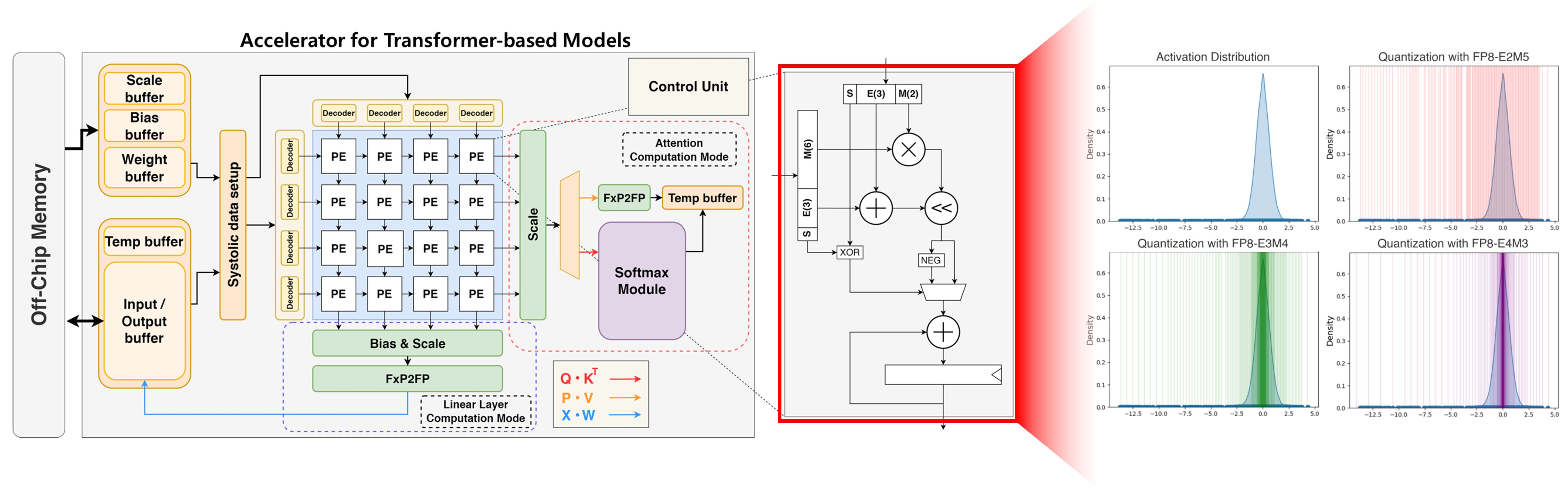
- Accelerator for Transformer Architecture
Transformer architecture has become the foundation for many state-of-the-art models in NLP and computer vision tasks. While it demonstrates high performance by capturing long-range dependencies through the attention mechanism, its quadratic complexity and large number of parameters pose challenges for deployment in various environments. GPUs are commonly used to support inference for such Transformer-based architectures, but they suffer from issues such as kernel launch overhead, low utilization, high power consumption, and high cost. Therefore, adopting a specialized architecture tailored for Transformer is crucial for achieving efficiency. We are particularly interested in accelerator architecture for Transformer that considers hardware implementation cost, external memory access overhead, processing element (PE) utilization, and data reuse. - SW/HW Co-design for model compression
Inference of neural networks involves significant computation and memory access. However, such neural networks exhibit substantial inherent redundancy, and various model compression techniques—such as quantization and sparsity—have been actively studied to exploit this characteristic. Nevertheless, many of these studies assume execution on general-purpose processors, which can limit the exploitation of compression opportunities. We are interested in software/hardware co-design approaches that explore a wide range of model compression techniques, including quantization, sparse attention, and token pruning/merging, along with accelerator architectures tailored to these methods.
Model Compression
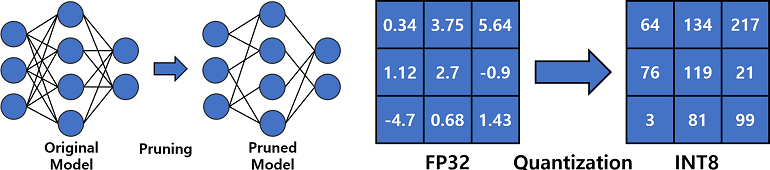
In deep learning, model compression is the key technique in real-world applications and model deployment. The goals of the model compression are as follows; minimizing the model size and decreasing model inference latency, and these goals can be achieved by various methods such as pruning, knowledge distillation, factorization, quantization, and so on.
Our research interest is pruning and quantization among model compression techniques.
Pruning eliminates redundant parts of weight parameters to make the network smaller and lower the computation cost, and pruning could be done elements-wise, or in structural manners; row/col/channel-wise.
Quantization reduces the number of bits required to represent the model, such as weights and activation. Quantization can reduce the size of the model. It can also decrease inference latency by using a dedicated framework and hardware.